
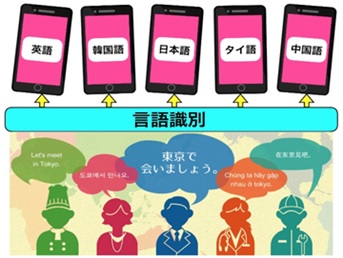
国立研究開発法人情報通信研究機構(NICT)は、人の発話が何語であるのかを入力音声のみから識別する日、英、中、韓、タイ、ミャンマー、ベトナム、インドネシアの8言語の言語識別技術を開発した。
従来の一般的な方式では、10秒程度の長い発話でないと識別が困難であるため、実際の音声アプリケーションではあまり使われていなかった。これに対して、言語識別に必要な発話の特徴を精度よく抽出し、かつ高速演算できるニューラルネットワークを提案し、1.5秒程度の短い発話でも0.15秒以内に即座に識別技術を開発した。
言語識別の公開アプリケーションとしては、グーグル社が提供する音声翻訳アプリに搭載された2言語識別機能及び4言語識別アプリがある。これらは、スマートフォン用音声翻訳アプリやスマートスピーカにおいて、指定した2言語及び4言語の中から言語識別を行う機能。今回、NICTが開発した方式は、倍の8言語を即座に翻訳できる。
これにより、何を話しているか分からない外国人の言葉も即座に識別し、言語設定の必要もなく音声認識や自動翻訳ができるようになる。今後、識別言語数の拡張、識別精度向上を図っていく。また、音声翻訳アプリケーションに実装するとともに、民間企業にライセンスする予定。
多言語音声認識、機械翻訳、音声合成の研究開発に取り組んでいるNICTでは、スマホ用アプリを実証実験のために無料公開している。音声アプリの大半は、入力される言語が何語であるかをあらかじめ指定する必要があるため、ユーザにとって不便だった。さらに、相手が話している言語が分からない場合には、何語かを指定すること自体が困難だった。
これを解決する方法として、入力発話が何語なのかを識別する言語識別技術がある。従来の一般的な方式では、10秒程度の長い発話ではないと識別が困難であるため、実際の音声アプリでは使いにくいという課題がある。
今回NICTは、この課題を解決するために、言語識別に必要な発話の特徴を精度よく抽出できる長い発話用のニューラルネットワークを変換して、短い発話でも識別精度が高く、かつ、リアルタイムで識別可能な小規模ニューラルネットを構築する方式を提案した。
この方式により、短い発話でも即座に識別できる技術を開発し、8言語で90%以上の識別率を実現した。この技術により、これまで必要であった入力言語の事前指定が不要となるため、何語を話しているか分からない外国人の言葉も即座に識別し、音声認識、機械翻訳ができるようになる。NICTでは、10月25日から27日まで開催された「けいはんな情報通信フェア」にデモ展示し、注目を集めた。







Copyright 株式会社官庁通信社 All Rights Reserved.
