
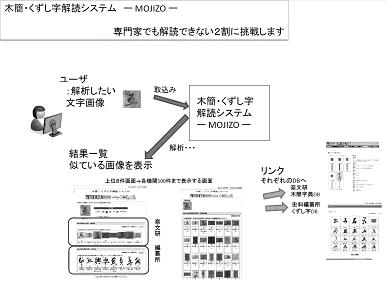
東京大学史料編纂所と奈良文化財研究所は、これまでの文字から検索する(文字引き)連携検索システムとは別に、画像から検索する(画像引き)連携検索システム「木簡・くずし字解読システム‐MOJIZO‐」を開発した=下図=。文字による検索に加え、画像による検索も可能になり、文字が読めなくても似た字形を探しだすことが可能となる画期的なデータベースとなることが期待される。
東大史料編纂所と奈文研では、2009年5月にデータベース連携に関する覚書を締結し、機関の枠組を越えた連携を行っている。2009年10月に公開した「『文字画像データベース・木簡字典』『電子くずし字字典データベース』連携検索」は、1000年以上にわたるわが国の文字を簡易に検索できるデータベースとして、研究者だけでなく、一般にも広く利用されている。
東大史料編纂所では、古文書・古記録・編纂物に書かれた文字を読み解くため、奈文研では地中から発掘された木簡に記された文字を読むため、それぞれ字形・字体の画像を集めたデータベースを開発し公開を進めてきた。
『電子くずし字字典データベース』『木簡画像データベース・木簡字典』の両データベースは、対象とする資料は異なるものの、字を読むツールとしてのコンセプトや機能で共有する部分が大きく、2009年以来、機関の壁を越えて、連携検索を実現してきた。双方あわせて30万件を超える字形画像と付随するメタデータを蓄積し、利用実績も年間10万件を超えるなど、学界を支える基本的インフラとして認識されている。
蓄積されたデータをさらに多くの人々に利活用してもらうためには、字形やメタデータから検索するだけでなく、実際に読めない文字画像を切り取ってシステムに投げかけ、蓄積データから類似のものを導きだす機能が必須となる。いわば歴史史料を読むためのOCR(光学文字認識)の必要性が高まっているといえる。
同様のOCR機能の開発は、さまざまな主体によってここ数年進められているが、典拠となるデータ群の大きさや確実性は、史料編纂所と奈文研が他機関よりも優れている。収集の対象も、古代から近代初頭に及び、木簡・石碑・文書・記録と典拠のバリエーションも多岐にわたっている。
そこで両機関は、情報学研究者の援助を得て、典型的な字形3万余件を選んでさまざまに解析を進め、任意の字形画像に対して、近似するものを瞬時に、ネットワーク上で表示しうるシステムを開発した。同機能はMOJIZOとして、3月末から両機関のホームページで無料公開する予定。
MOJIZOの公開によって、文字史料は専門家以外の多くの人々にとって身近になることが期待される。身近にある石碑や古文書、軸物などの眺めるだけだった存在が、読み語る対象に変化し、文字史料は専門家に独占されるものではなく、生涯学習や学校教育のなかでも活用される貴重な素材になる。
東大史料編纂所や奈文研では、こうしたことを通して、木簡などに対する関心が深まることで、遺跡や史料を保全する意識一般に広がり、埋蔵文化財や歴史を研究する研究者にとっても大きな利益となると期待している。







Copyright 株式会社官庁通信社 All Rights Reserved.
